No-SQL
Acid and Base
- Atomic: Each task in a transaction succeeds or the entire transaction is rolled back.
- Consistent: A transaction maintains a valid state for the database before and after its completion and cannot leave the database in an inconsistent state.
- Isolated: A transaction not yet committed must not interfere with another transaction and must remain isolated.
- Durable: Committed transactions persist in the database and can be recovered in case of database failure. While these characteristics seem obvious for most of the applications, they are not suitable for horizontal scaling, high availability, performance and fault tolerance.
The alternative to ACID is BASE which is what NoSQL databases follow:
- Basically Available: The system is guaranteed to be available in event of failure.
- Soft State: The state of the data could change without application interactions due to eventual consistency.
- Eventual Consistency: The system will be eventually consistent after the application input. The data will be replicated to different nodes and will eventually reach a consistent state. But the consistency is not guaranteed at a transaction level.
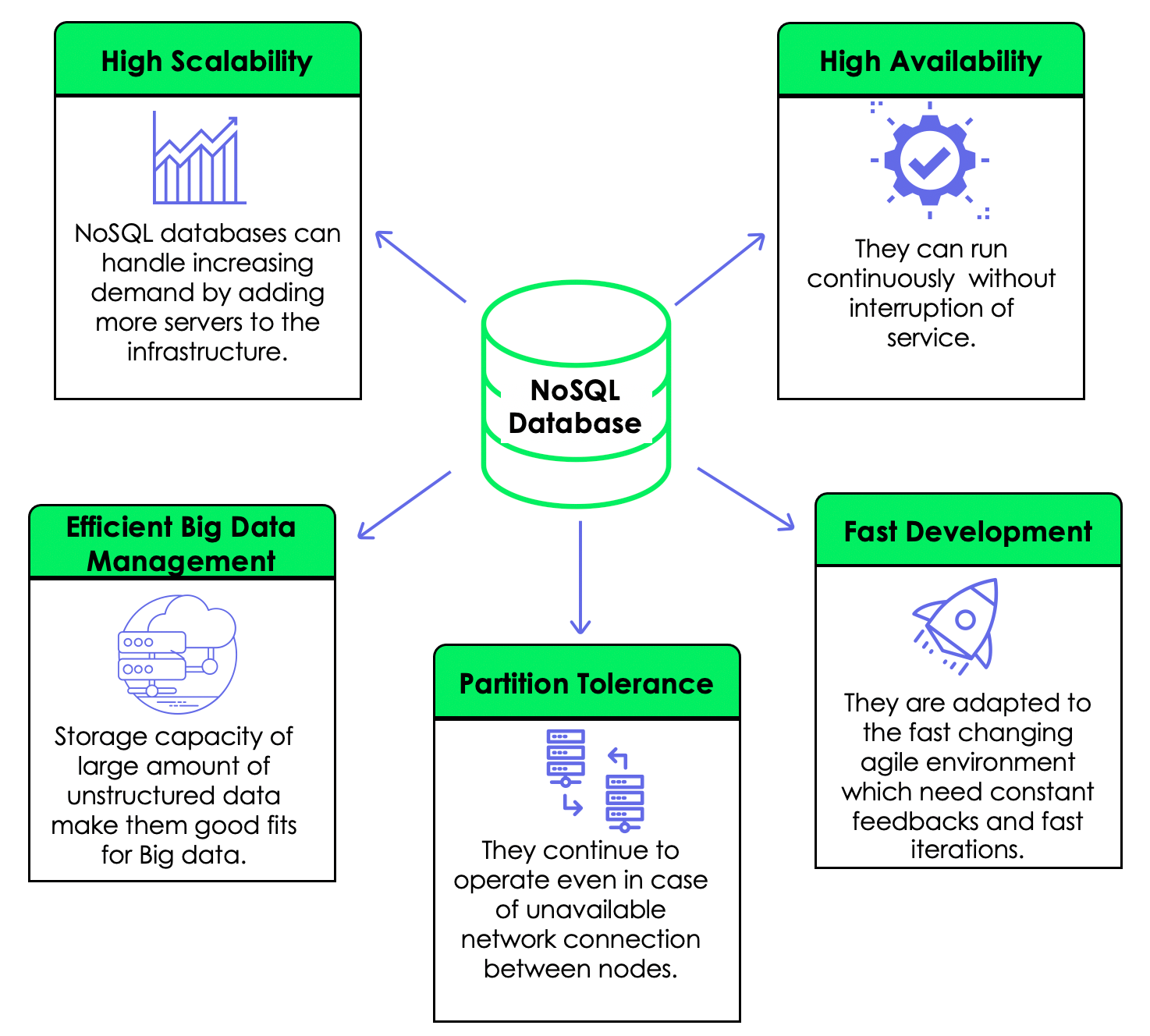
The BASE systems allow horizontal scaling, fault tolerance and high availability at the cost of consistency. So, if your application requires high availability and scalability, a NoSQL Database built on BASE properties might be suitable.
CAP Theorem
The CAP Theorem quantifies tradeoffs between ACID and BASE and states that, in a distributed system, you can only have two out of the following three guarantees: Consistency, Availability, and Partition Tolerance, one of them will not be supported.
- Consistency: All nodes in the cluster have consistent data and a read request returns the most recent write from any node.
- Availability: A non-failing node must always respond to requests in a reasonable time
- Partition Tolerance: System continues to operate during network or node failures.
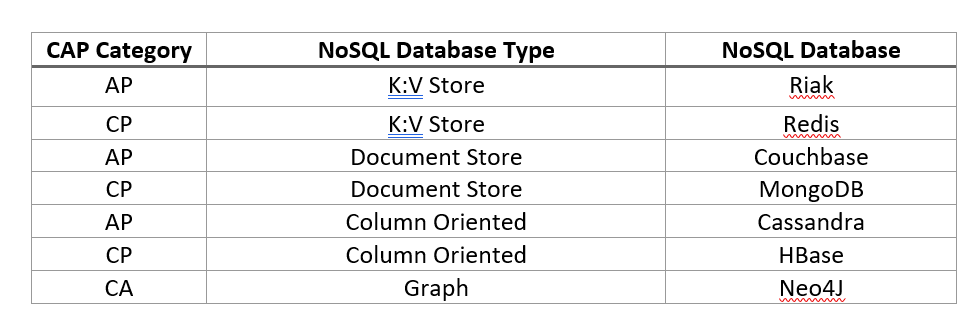
As per CAP theorem, we must choose from CA, AP or CP characteristics for a given system. This offers a way to categorize databases and provides guidance on determining which database shall be a good fit for your application.
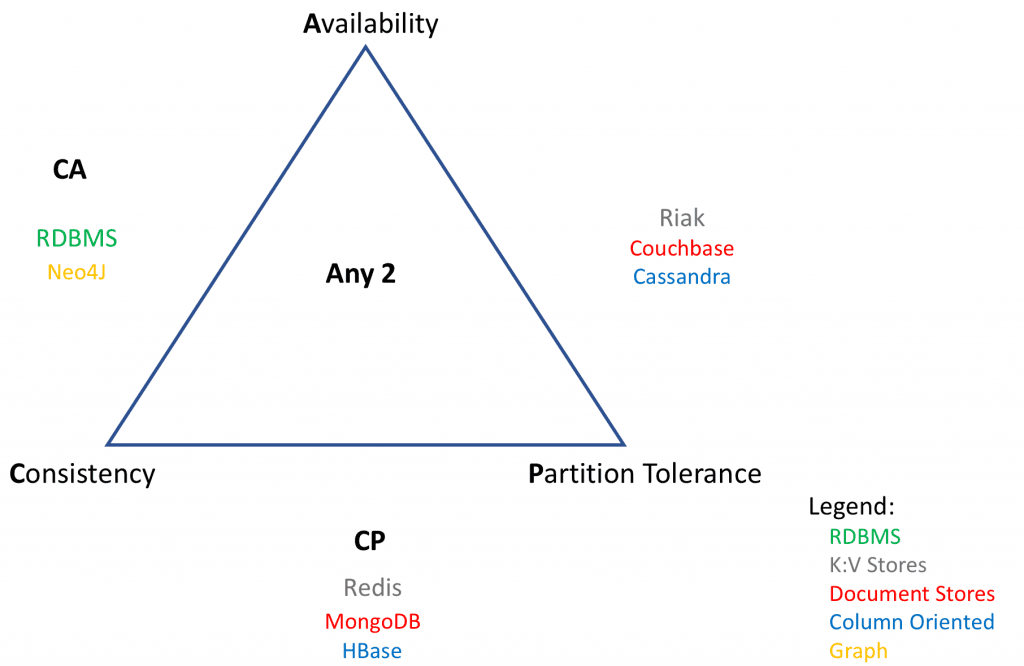
- Consistent and Available System: If your application requires high consistency and availability with no partition tolerance, a CA system is a good fit. Most of the traditional RDBMS are CA systems but we have ruled them out from our fit analysis in stage 1. A Graph Database such as Neo4j is also a CA system and will be analyzed in stage 3 of the fit analysis.
- Consistent and Partition Tolerant System: If your application requires high consistency and partition tolerance, a CP system is a good fit. CP systems are not able to guarantee availability as the system returns error until the partitioned state is resolved. Redis (K:V), MongoDB (Doc Store) and HBase (Col Oriented) are examples.
- Available and Partition Tolerant System: If your application requires high availability and partition tolerance, a AP system is a good fit. AP systems are not able to guarantee consistency as writes/updates can be made to either side of the partition. Such systems usually provide GDHA (Geographically Dispersed High Availability) where data is bi-directionally replicated across two datacenters and both are in Active-Active configuration i.e. application can write/read to/from either datacenter. Riak (K:V), Couchbase (Doc Store) and Cassandra (Col Oriented) are examples.
After analyzing the CAP requirements for your application, you can narrow down to a set of NoSQL databases from the selected CAP category for further consideration.
why no-sql
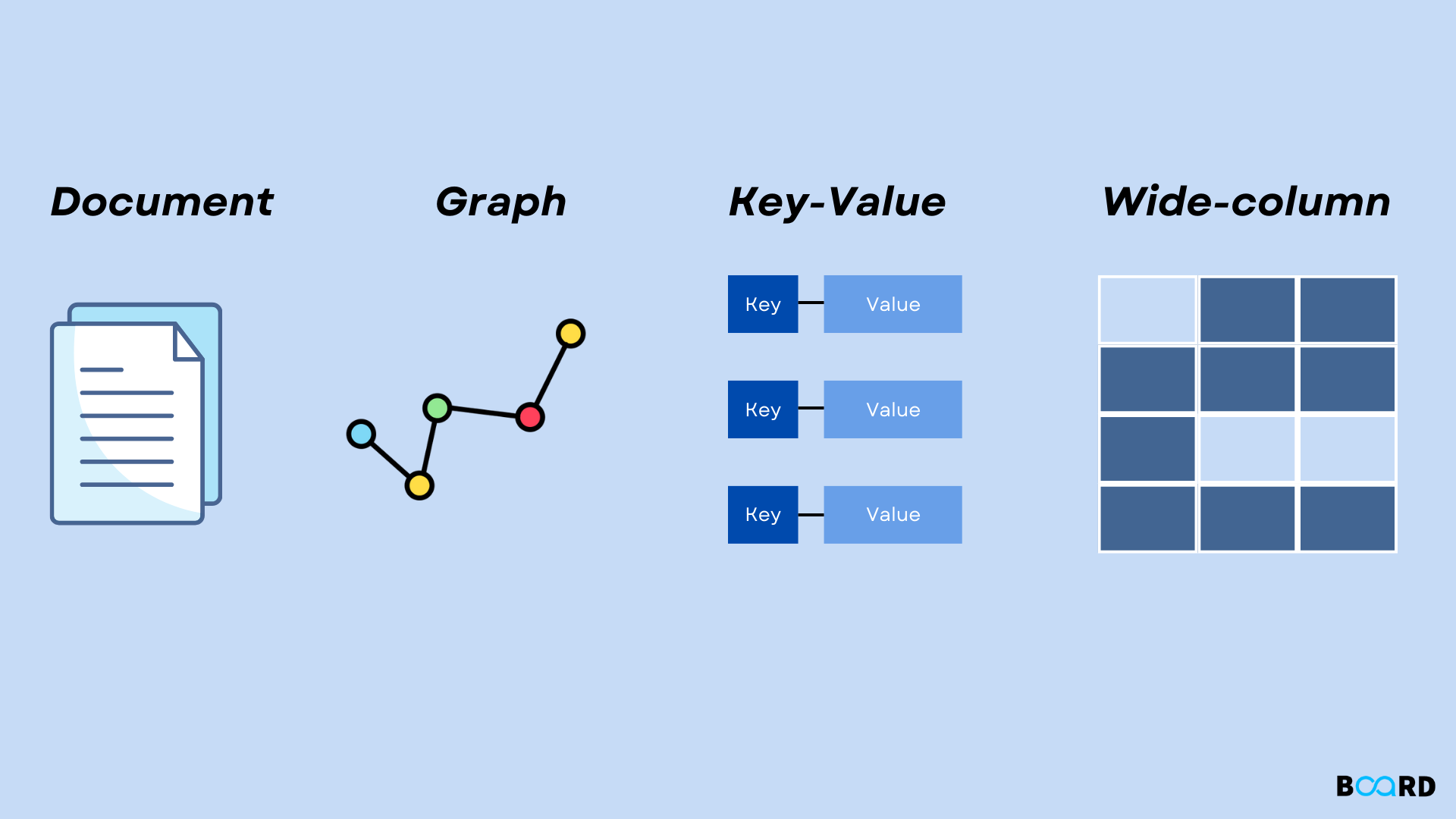
Types of no-sql
Examples from the market

1. Document Databases
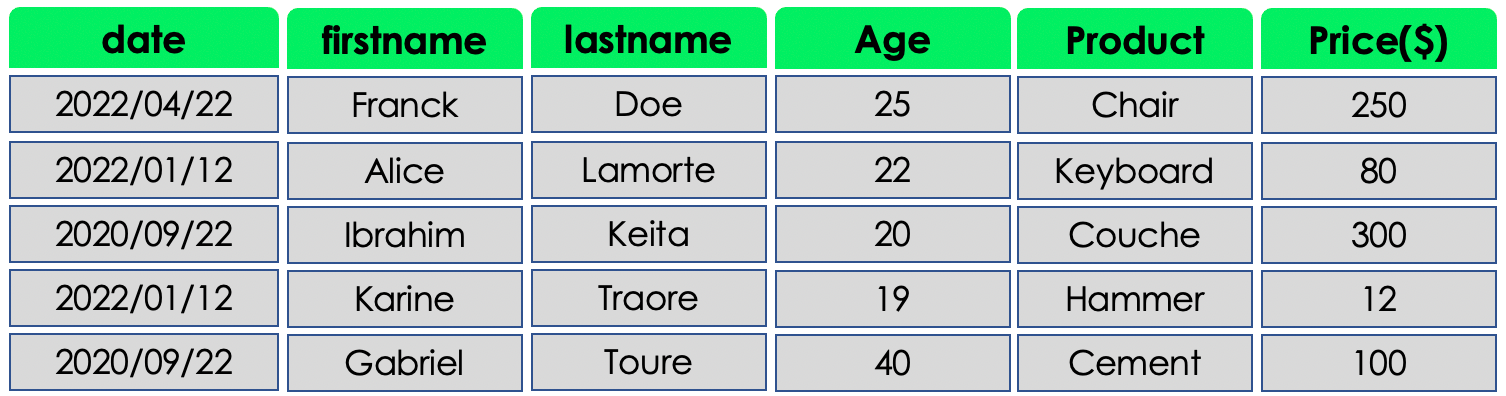
This type of database is designed to store and query JSON, XML, BSON, etc., documents. Each document is a row or a record in the database and is in the key-value format. A document stores information about one object and its related data. For instance, the following database contains three records, each one gives information about a student. For the first document, firstname is a key, and Franck is its value.
Document Database Advantages
- Schemaless: there are no limitations in terms of the format and structure of the data storage. This is beneficial, especially when there is a continuous transformation in the database.
- Easy to update: a piece of new information can be added or deleted without changing the rest of the existing fields of that specific document.
- Improved performance: all the information about a document can be found in that exact same document. There is no need to refer to external information, which might not be the case for a relational database where the user might have to request other tables.
Document Database Limitations
- Consistency check issues: because documents do not necessarily need to have a relationship with one another, and two documents can have different fields.
- Atomicity issues: If we have to change two collections of documents, we will need to run a separate query for each document.
When to Use Document Databases
- Recommended when your data schema is subject to constant changes in the future.
Document Database Applications
- Because of their flexibility, document databases can be practical for online user profiles, where different users can have different types of information. In this case, each user’s profile is stored only by using attributes that are specific to them.
- They can be used for content management, which requires effective storage of data from a variety of sources. That information can then be used to create and incorporate new types of content.
2. Key-value Databases
These are the simplest types of NoSQL databases. Every item is stored in the database in a key-value pair. We can think of it as a table with exactly two columns. The first column contains a unique key. The second column is the value for each key. The values can be in different data types, such as integer, string, and float, or more complex data types, such as image and document.
The following example illustrates a key-value database containing information about customers where the key is their phone number, and the value is their monthly purchase.
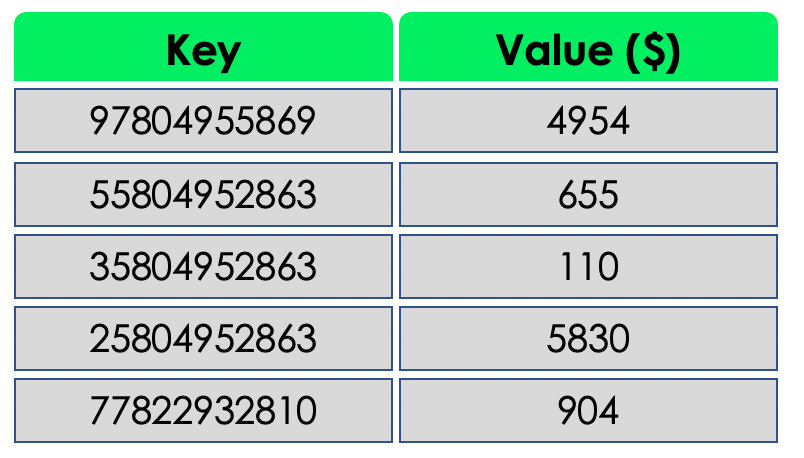
Key-value Database Advantages
- Simplicity: the key-value structure is straightforward. The absence of data type makes it simple to use.
- Speed: the simple data format makes read and write operations faster.
Key-value Database Limitations
- They cannot perform any filtering on the value column because the returned value is all the information stored in the value field.
- It is optimized only by having a single key and value. Storing multiple values would require a parser.
- The value is updated only as a whole, which requires getting the complete data, performing the required processing on that data, and finally storing back the whole data. This might create a performance issue when the processing requires a lot of time.
When to Use Key-value Databases
- Adapted for applications based on simple key-based queries.
- Used for simple applications that need to temporarily store simple objects such as cache.
- They can be used as well when there is a need for real-time data access.
Applications
- They are better for simple applications that need to temporarily store simple objects such as cache.
3. Wide-column Databases
As the name suggests, column-oriented databases are used to store data as a collection of columns, where each column is treated separately, and the implementation logic is based on Google Big Table paper. They are mostly used for analytical workloads such as business intelligence, data warehouse management, and customer relationship management.
For instance, we can quickly get the average age and average price respectively of customers and products with the aggregation function AVG on each column.
4. Graph/node Databases
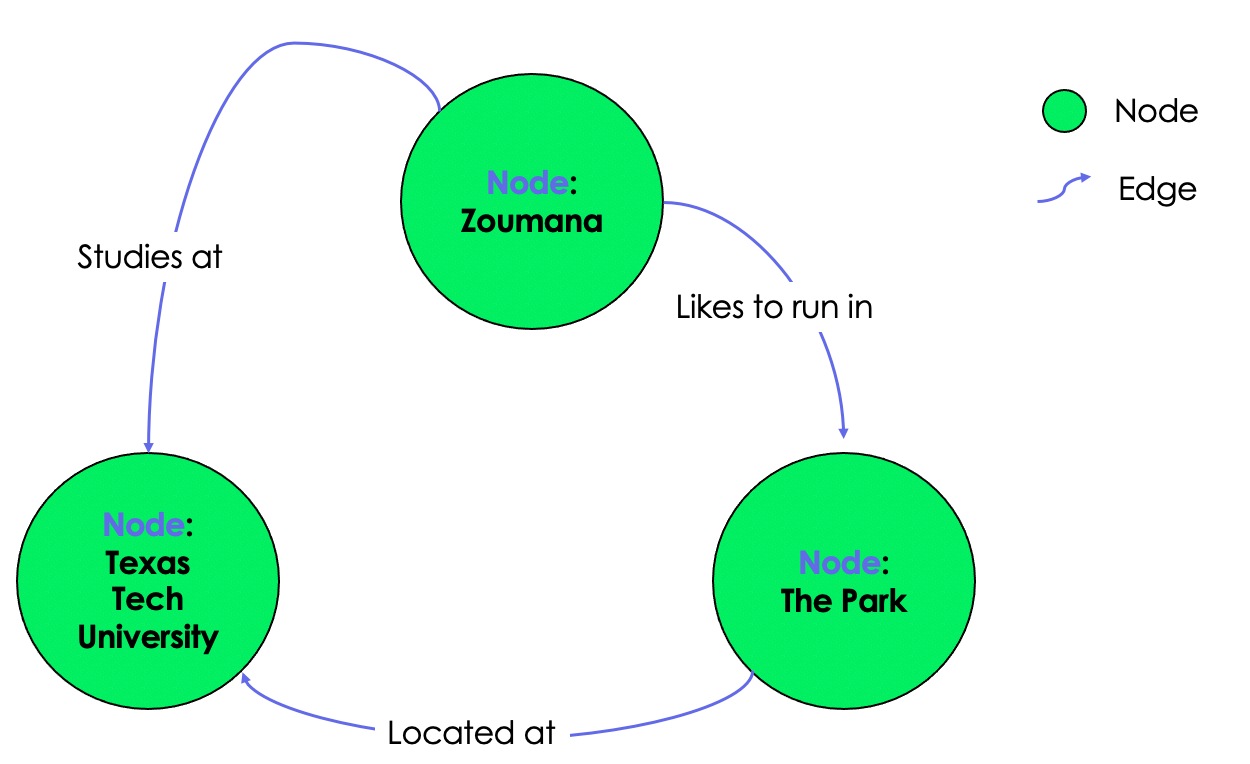
Graph databases are used to store, map and search relationships between nodes through edges. A node represents a data element, also called an object or entity. Each node has an incoming or outcoming edge. An edge represents the relationship between two nodes. Those edges contain some properties corresponding to the nodes they connect.
“Zoumana studies at Texas Tech University. He likes to run at the Park inside the University”
Graph/node Database Advantages
- They are an agile and flexible structure.
- The relationship between nodes in the database is human readable and explicit, thus easy to understand.
Graph/node Database Limitations
- There is no standardized query language because each language is platform-dependent.
- The previous reason makes it difficult to find support online when facing an issue.
When to Use Graph/node Databases
- They can be used when you need to create relationships between data elements and be able to quickly retrieve those relationships.
Applications
- They can be used to perform sophisticated fraud detection in real-time financial transactions.
- They can be used for mining data from social media. For instance, LinkedIn uses a graph database to identify which users follow each other, and the relationship between those users and their expertise (ML Engineer).
- Network mapping can be a great fit for representation as a graph since those networks map relationships between hardware and the services they support.
Determine NoSQL Database Type
As you may have noticed in stage 2, each CAP category contains more than one NoSQL Database types (K:V/Document Store/Column Oriented/Graph). In this stage, we further analyze the application purpose & use case to determine which NoSQL Database type should be considered from the CAP category chosen for your application.
NoSQL Database types are designed for a specific group of use cases. I have listed some of the key use cases for each NoSQL Database type. You can use this list as a starting point for analyzing your application’s requirements.
Choose K:V Stores if:
- Simple schema
- High velocity read/write with no frequent updates
- High performance and scalability
- No complex queries involving multiple keys or joins
Choose Document Stores if:
- Flexible schema with complex querying
- JSON/BSON or XML data formats
- Leverage complex Indexes (multikey, geospatial, full text search etc)
- High performance and balanced R:W ratio
Choose Column-Oriented Database if:
- High volume of data
- Extreme write speeds with relatively less velocity reads
- Data extractions by columns using row keys
- No ad-hoc query patterns, complex indices or high level of aggregations
Choose Graph Database if:
- Applications requiring traversal between data points
- Ability to store properties of each data point as well as relationship between them
- Complex queries to determine relationships between data points
- Need to detect patterns between data points
Now you have decided the CAP category and the NoSQL type for your application. At this stage if we perform a fit analysis based on the select NoSQL databases shown in Fig 1, our decision matrix would look as follows:
But as a last step, we also need to consider the database and technology characteristics of each NoSQL Database and the requirements from the application and organization to finalize a selection. These are detailed in step 4.
Select NoSQL Database (Vendor)
Even after selecting a CAP category and NoSQL Database type, the fit analysis is not complete. Selection of a NoSQL Database also depends on the database technology, its configuration and available infrastructure, proposed architecture of your application, budget as well as the skill set available at your organization etc.
Database considerations:
- Backup and recovery configurations
- Cluster topology: GDHA / HADR, Active-Active / Active-Passive
- Replication: Synchronous, Asynchronous or Quorum
- Read/Write concerns and Indexing strategies
- Concurrency control: Locks, MVCC (Multi Version Concurrency Control), Read Your Own Write (RYOW)
- Security, access controls and encryption at rest
- Available APIs and Query methods: JSON, XML, REST, Thrift, CQL, MapReduce, SPARQL, Cypher, Gremlin etc.
- Infrastructure: On-premise or Cloud / Dedicated or Shared
- Database uptime categorization (99.9% up to 99.999%)
Architecture/Application considerations:
- Application Requirements: Use cases, R:W patterns, performance expectations/SLAs, upstream/downstream systems, criticality to the business etc.
- Implementation Language and SDKs: C/C++, Java, Python, Node.Js etc
- Application Architecture: Web Application, Microservices, Mobile etc.
- Data Integration: Batch processing, ETL, Streaming, Message broker, ESB etc.
- Complementary Technologies: Spark, Storm, Kafka, ELK, Solr, Splunk etc.
Organization considerations:
- Budget and cost considerations
- Team skillset
- Preferred vendors / existing technology stack
- Motivation for NoSQL/Big Data
- Business / Technology leadership sponsorship & support
more concepts
gossip protocol

important thing to remember
- there is no leader in gossip.
-
all are equal.
- bootstrapping

- secondary index

- data model
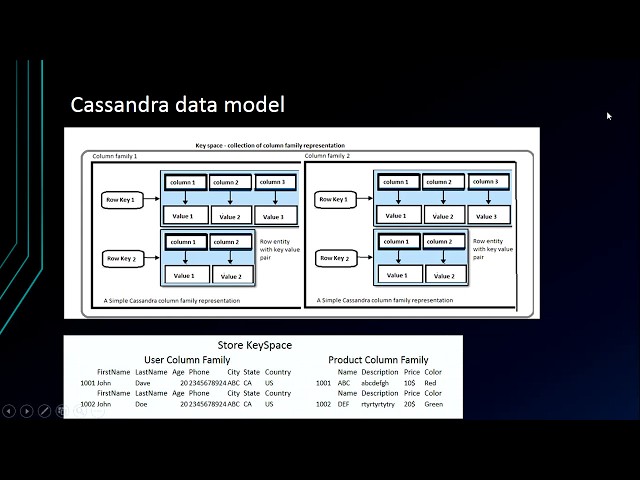
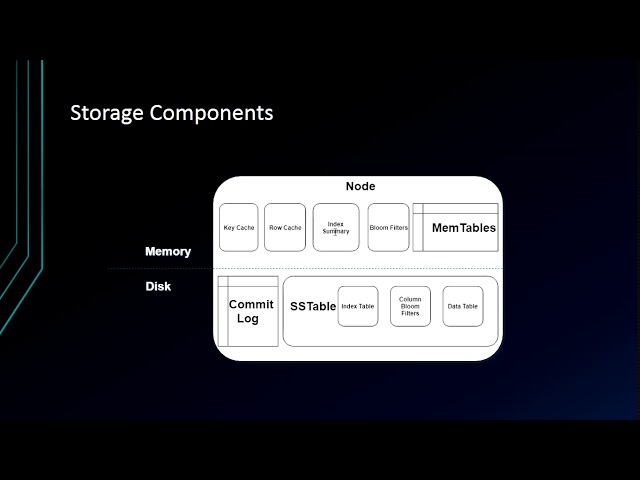
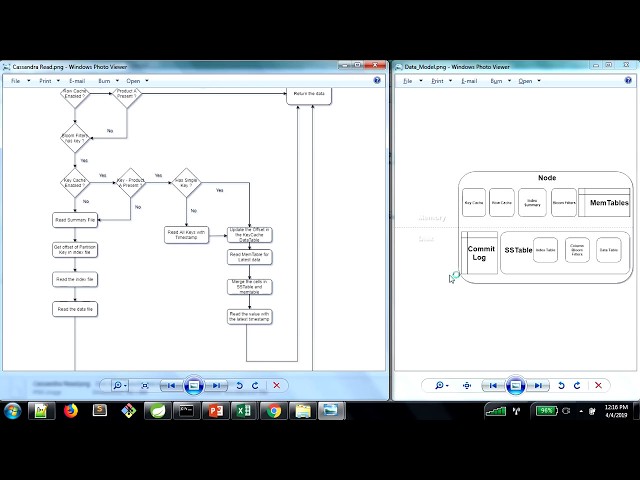
complete kafaka
https://www.youtube.com/playlist?list=PLa7VYi0yPIH14oEOfwbcE9_gM5lOZ4ICN
best webrtc
https://www.youtube.com/watch?v=DOe7GkQgwPo&ab_channel=AmirEshaq
consistancy levels of cassandra
ONE Returns data from the nearest replica.
QUORUM Returns the most recent data from the majority of replicas.
ALL Returns the most recent data from all replicas.